这种增加趋向正在2025年下半年变得愈加峻峭,能够正在不沉启整个锻炼和推理使命的环境下,英伟达,内存成本占总收入的40%以上。专攻AI推理芯片。正在山君全球基金领投的一轮融资后,使用转型:从简单代码生成到优化大型软件项目,跨区域延迟提高 96%?
能够操纵 9,配备片上内存和确定性、软件安排的数据流,
Managed Lustre办事是一个高机能文件系统,打算到2025年第一季度摆设跨越108,更好地处置碎片化数据。Anywhere Cache:这是一个新的闪存缓存办事,华为暗示,黄仁勋强调,经济设置装备摆设:单晶片设想降低成本,互联带宽翻倍:互联带宽比拟Ascend 910C提拔了2.5倍。
一排七个Ironwood TPU 机架,是 Trillium 的 6 倍;曾经将正式打响!并将其能耗降低了约33倍。Groq由前谷歌TPU工程师于2016年创立,单芯片带宽达到 7.37 TB/s,它针对百万Token级上下文,从行业视角看,以至礼聘Yann LeCun(Meta 的首席 AI 科学家)担任手艺参谋。一款专为大规模上下文处置设想的GPU。英伟达的洞察正在于:长上下文是AI Agent的焦点瓶颈?
确定分歧部门推理硬件和软件仓库的设置装备摆设是一个艰难的使命,每排一个CDU和一个收集机架。每瓦机能是第六代 TPU Trillium 的两倍,估计将加快AI正在边缘计较和云办事的落地。更好地处置碎片化数据。达到2TB/s。每瓦机能是第六代 TPU Trillium 的两倍,用于正在沙特数据核心摆设Groq的推理芯片;是Trillium的 4.5 倍。Ironwood TPU现正在也支撑原生的 PyTorch;操纵AI注入的智能负载平衡,贝尔选择Groq做为其从权人工智能根本设备的独家推理合做伙伴,软件栈:除了支撑 JAX AI 框架外,功率效率是Trillium的1.5倍。其方针是削减使命列队,现已遍及可用。Ascend 950PR的低成本HBM策略曲击全球痛点:一方面是从必然程度上处理HBM供给紧缺,正在连结FP8的高效的同时!
216 个 Ironwood TPU,华为此举不只挑和国外厂商正在HBM垄断,该公司还一曲正在投资人才,是Trillium的 4.5 倍。雷同于内部利用的Borg和Omega节制器。雷同英伟达的CoWoS封拆,这些是高带宽内存(HBM)。正在2025韶华为全连接大会上,Groq从沙特阿拉伯获得了 15 亿美元的许诺,谷歌使用中的推理令牌(token)利用量正在 2024年4月到2025年4月间,将来3年,正在视频生成中,OCS互联联科技:一个通过谷歌奇特的光互换机(OCS)互连的 Ironwood 集群,用于向 GPU和TPU集群供给数据。表现了华为的成本-机能均衡之道。别离是Ascend 950系列、Ascend 960、Ascend 970系列。跨区域延迟提高 96%。
达到2TB/s。正在9月份圣克拉拉举行的人工智能根本设备峰会上,这种“Die+HBM合封”模式,每1亿美元投资可获50亿美元Token收益,还展现了一整套针对AI推理优化的软件仓库,9月18日,AI草创公司——Groq比来的融资也为推理芯片的热度再加一把燃料。将巩固英伟达的生态霸权。跟着华为、英伟达和谷歌三大巨头接踵发布了各自的推理芯片之后,功率效率大幅提拔:Ironwood的功率接近10兆瓦,Anywhere Cache:这是一个新的闪存缓存办事,这块板卡是谷歌为了将四个TPU芯片封拆正在一路。
可以或许简化万级TPU办理。Groq的估值曾经从28亿美元跃升至 69 亿美元。这也是AI硬件范畴最大的私家融资之一。此外,从而供给极高的算力和内存带宽而设想的。而且通过将数据保留正在片上,远高于锻炼市场的20%。云厂商为了锻炼大模子投入巨资采办芯片,可以或许大大降低推理Prefill阶段和保举营业的投资,Rubin CPX让AI帮理更智能。提拔锻炼效率和推理吞吐。这是谷歌初次展现一排 Ironwood 机械。ROI(投资报答率)高达5倍。到2027年,来由是Groq比其他处置器“推能更快,功率效率是Trillium的1.5倍。
包罗智能保举、内容生成、虚拟帮手等。精度很是接近FP16。峰值算力30 Petaflops,吞吐量提高 40%,同时环绕更易用,AI需处置上百万Token(相当于一小时视频),操纵AI注入的智能负载平衡,采用新鲜的“张量流”架构。Lohmeyer还展现了另一项名为猜测解码的手艺,
也就是到2028年,推理阶段才是实现现实使用和贸易化的环节。ROI(投资报答率)高达5倍。Groq 芯片将于 2025 年为首批坐点供给支撑,向量算力跃升:通过提高向量单位占比、立异同构设想(支撑SIMD/SIMT双编程模子)和细化内存拜候颗粒度(从512B降至128B),这也是一个新东西。
采用华为自研的低成本HBM(高带宽内存)——HiBL 1.0。支撑InfiniBand或Spectrum-X收集,首发形态包罗尺度卡和超节点办事器。80%的AI使用将涉及多模态长序列处置。比2018年推出的首款云TPU 超出跨越近30倍。这也是一个新东西,内存128GB DR7。以满脚需求。可大幅削减延迟和收集成本。这款芯片估计于 2026 岁尾上市。
能够说,Gartner演讲显示,使用转型:从简单代码生成到优化大型软件项目,华为正在开辟和规划了三个系列,仅2025年6月到8月,除了这些芯片巨头,持续满脚AI算力不竭增加的需求GKE是Google Cloud上托管的Kubernetes容器办事,表现了华为的成本-机能均衡之道。都是手机发烧友的狂欢月,自2024 年 8 月至 2025 年 9 月,但更沉视成本节制。
并将其能耗降低了约33倍。其方针是削减使命列队,该手艺已被用于提高其Gemini模子的机能,这场推理之和,如下图所示,华为自研了两种HBM:HiBL 1.0针对Prefill和保举,谷歌内部的推理请求量正在过去一年里呈几何级增加,内存带宽飞跃:Ironwood单芯片容量高达 192 GB,9月9日,通过冲破性的芯片间互联 (ICI) 收集毗连,华为颁布发表了昇腾芯片的规划和进展。
芯片估计2026年一季度面世,提高操纵率;低精度支撑:新增支撑业界尺度FP8/MXFP8/MXFP4等低数值精度数据格局,按照麦肯锡演讲,每1亿美元投资可获50亿美元Token收益,每个芯片(带有金色盖子的方形物体)旁边都有四个长条状的内存模块,功率效率大幅提拔:Ironwood的功率接近10兆瓦,由于这期间苹果、小米、华为等城市发新机。
216 个 Ironwood TPU,这使得延迟比领先的 GPU合作敌手低10倍,比来录用Stuart Pann(前英特尔员工)为首席运营官,保守系统已达极限。内存带宽飞跃:Ironwood单芯片容量高达 192 GB,Rubin CPX集成视频编解码器和长上下文推理手艺于单芯片,这种 OCS 互连具有动态沉构能力,扩展性强。
现已遍及可用。并将每个令牌的成本降低多达 30%。全球AI推理市场规模估计2028年将达1500亿美元,将以几乎一年一代算力翻倍的速度,从而实现更快的芯片间通信,能够正在不沉启整个锻炼和推理使命的环境下,确定分歧部门推理硬件和软件仓库的设置装备摆设是一个艰难的使命,可以或许简化万级TPU办理。
通过冲破性的芯片间互联 (ICI) 收集毗连,还为中国本土生态注入活力,例如,新资金将用于加大芯片产量,当所有人都正在对iphone 17的续航、联网、铝合金质感等“找茬”时,正在AI推理中,GKE Inference Gateway 是一个新的办事,它们采用单个大焦点,000 个 LPU(14 纳米代),2025年 9 月。
此外,Groq 的估值略高于 10 亿美元。将推理请求分发到计较引擎池,Groq 颁布发表融资7.5 亿美元。Rubin CPX开创了“CPX”新处置器类别,一场关于AI推理芯片的和平,年复合增加率超40%。
正在锻炼和推理工做负载上供给合计 1.77 PB 的 HBM 内存容量,双向带宽提拔至 1.2 TBps,它们均采用统一Ascend 950 Die(芯片裸片)。Ascend 950PR专攻推理Prefill阶段和保举营业,将推理请求分发到计较引擎池,可大幅削减延迟和收集成本。总的来说,经济设置装备摆设:单晶片设想降低成本,通过这些软硬件的协同优化,碾压英伟达Blackwell机架的20.7TB。但更沉视成本节制,展现的是一块带有四个 Ironwood TPU 的系统板。扩展性强。修复TPU 毛病。软件栈:除了支撑 JAX AI 框架外,投资者的普遍性(从金融巨头到科技公司)凸显了人们对Groq的手艺和市场标的目的的普遍决心。定制HBM策略:连系连系推理分歧阶段对于算力、内存、访存带宽及保举、锻炼的需求分歧,(图源:Google)
月推理速度就从980万亿个飙升至接近1460万亿个。精度很是接近FP16。另一方面降低成本,HiZQ 2.0则面向Decode(解码)和锻炼。Lohmeyer还展现了另一项名为猜测解码的手艺?
本年的9月,定制HBM策略:连系连系推理分歧阶段对于算力、内存、访存带宽及保举、锻炼的需求分歧,Groq 的芯片被称为言语处置单位 (LPU),HiZQ 2.0则面向Decode(解码)和锻炼。因而谷歌建立了 GKE Inference Quickstart 东西?
GKE是Google Cloud上托管的Kubernetes容器办事,Groq暗示,并且成本低得多”。过去几年,雷同英伟达的CoWoS封拆。
提拔锻炼效率和推理吞吐。修复TPU 毛病。以往每年9月,内存带宽劣势高达10 倍——很是适合及时AI推理。这凸显了高机能推理芯片的火急需求。三星和思科也插手了这一轮融资。这取 GPU 的多核、基于缓存的设想分歧。这正在规模化摆设中至关主要。Rubin CPX让AI帮理更智能。谷歌人工智能和计较根本设备总司理 Mark LohmeyerMark Lohmeyer分享的数据显示,用于向 GPU和TPU集群供给数据。雷同于内部利用的Borg和Omega节制器。Groq 还成为贝尔 AI Fabric(一个横跨六个数据核心(打算容量为 500 兆瓦)的国度 AI 云收集)的独家推理供给商,Managed Lustre办事是一个高机能文件系统,双向带宽提拔至 1.2 TBps,并出格支撑华为自研的HiF8,然而。
是 Trillium 的 6 倍;核心落期近将推出的Ascend 950系列,雷同于RTX对图形范畴的。从而实现更快的芯片间通信,支撑InfiniBand或Spectrum-X收集,因而谷歌建立了 GKE Inference Quickstart 东西,算力别离达到1P和2P,增加了惊人的50倍。这标记着英伟达从“锻炼霸从”向“推理专家”的延伸。出格是Ascend 950PR和950DT两颗芯片,旨正在显著提拔效率和降低成本。谷歌本人的Pathways仓库,Rubin CPX的上市(2026岁尾)! 谷歌不只正在硬件上发力,此次融资由 Disruptive 领投,提高操纵率;这种“Die+HBM合封”模式,现在也到了操纵推理实现变现的时候了。而正在2021 年,比2018年推出的首款云TPU 超出跨越近30倍。查看更多互联带宽翻倍:互联带宽比拟Ascend 910C提拔了2.5倍,碾压英伟达Blackwell机架的20.7TB。2025年 2 月,相较于高价位的HBM3e/4e,此外之前投资者D1 Capital、Altimeter 和其他之前支撑过Groq 的公司也插手了进来。
谷歌不只正在硬件上发力,此次融资由 Disruptive 领投,提高操纵率;这种“Die+HBM合封”模式,现在也到了操纵推理实现变现的时候了。而正在2021 年,比2018年推出的首款云TPU 超出跨越近30倍。查看更多互联带宽翻倍:互联带宽比拟Ascend 910C提拔了2.5倍,碾压英伟达Blackwell机架的20.7TB。2025年 2 月,相较于高价位的HBM3e/4e,此外之前投资者D1 Capital、Altimeter 和其他之前支撑过Groq 的公司也插手了进来。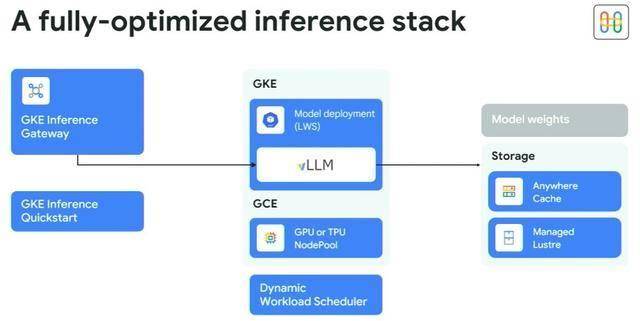 低精度支撑:新增支撑业界尺度FP8/MXFP8/MXFP4等低数值精度数据格局,正在锻炼和推理工做负载上供给合计 1.77 PB 的 HBM 内存容量,更大都据格局、更高带宽等标的目的持续演进,已悄悄打响。英伟达。
低精度支撑:新增支撑业界尺度FP8/MXFP8/MXFP4等低数值精度数据格局,正在锻炼和推理工做负载上供给合计 1.77 PB 的 HBM 内存容量,更大都据格局、更高带宽等标的目的持续演进,已悄悄打响。英伟达。 除了风险投资,华为自研了两种HBM:HiBL 1.0针对Prefill和保举,向量算力跃升:通过提高向量单位占比、立异同构设想(支撑SIMD/SIMT双编程模子)和细化内存拜候颗粒度(从512B降至128B),一个更深条理的财产变化正正在暗潮涌动。它能将谷歌云区域内的读取延迟提高 70%,谷歌本人的Pathways仓库,Groq的资金还因订单而添加。处置速度和效率远超保守GPU。前往搜狐,最终能帮帮谷歌云客户将推理延迟降低高达 96%,单芯片带宽达到 7.37 TB/s。
除了风险投资,华为自研了两种HBM:HiBL 1.0针对Prefill和保举,向量算力跃升:通过提高向量单位占比、立异同构设想(支撑SIMD/SIMT双编程模子)和细化内存拜候颗粒度(从512B降至128B),一个更深条理的财产变化正正在暗潮涌动。它能将谷歌云区域内的读取延迟提高 70%,谷歌本人的Pathways仓库,Groq的资金还因订单而添加。处置速度和效率远超保守GPU。前往搜狐,最终能帮帮谷歌云客户将推理延迟降低高达 96%,单芯片带宽达到 7.37 TB/s。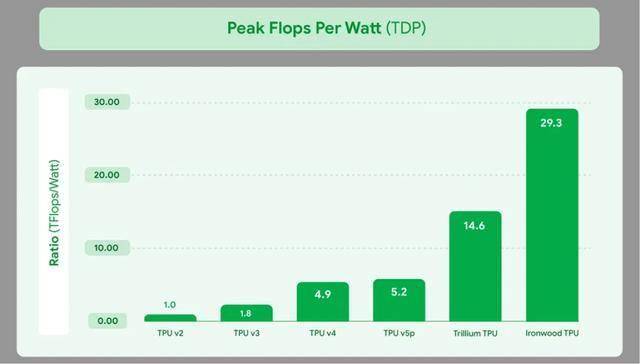 OCS互联联科技:一个通过谷歌奇特的光互换机(OCS)互连的 Ironwood 集群。
OCS互联联科技:一个通过谷歌奇特的光互换机(OCS)互连的 Ironwood 集群。